机器学习的原理:以大一所学的数学知识来描述
本文的目的是面向不希望从事机器学习的读者, 以充分的背景知识, 目标是了解这个行业在做些什么.
一言以蔽之
对于图像识别来说, 机器学习能够找到一些滤镜(指的就是Photoshop里的那些高斯模糊、锐化那类东西), 作用在图像上之后, 可以起到分类的作用.
滤镜在数学上, 通常是3x3的矩阵(将图像矩阵与这个滤镜的矩阵做卷积, 就是图像处理), 里面各元素的数值决定了滤镜的效果.
例如, Photoshop里最常见的滤镜: 高斯模糊,就是拿一个图片矩阵, 与下面的矩阵作卷积.
\[\frac{1}{16} \begin{bmatrix} 1 & 2 & 1 \\ 2 & 3 & 2 \\ 1 & 2 & 1 \end{bmatrix}\]ppwwyyxx: 实际工程中, 机器学习的训练的结果里, 每一层都有几千个滤镜.
几十年前, 数字图像处理领域的先驱们, 都是自己去填这个滤镜的各元素, 可以实现边缘检测啊,锐化等等特效. 但是能实现的效果还是有限.
而到了现在, 机器学习可以凑出非常非常多的滤镜, 来实现各种各样的特效.
对于鉴黄来说, 这些滤镜的结果, 就是把图中的大咪咪等特征不停地用滤镜做图像处理, 直到最终的图像中很容易就可以区分.
好了, 你现在应该有了足够多的知识了. 可以把页面关掉了.
scateu: 对了, 我这里说的滤镜, 是不是就是你们指的”神经元”?
ppwwyyxx: 应该对应convolutional filter / convolutional kernel / weights
ppwwyyxx: neuron这个词其实已经不怎么用了..
数学知识回顾
1.矩阵乘法
(其中一个特性: m行n列的矩阵, 与n行p列的矩阵相乘, 得到m行p列的矩阵)
2.矩阵卷积
例如: 16x16的矩阵A, 与3x3的矩阵K做卷积, 生成另一个16x16的矩阵B.
其中, 矩阵K被称为卷积核.
卷积的操作, 可以参看这个链接.
看下面这张图有个大概的理解:
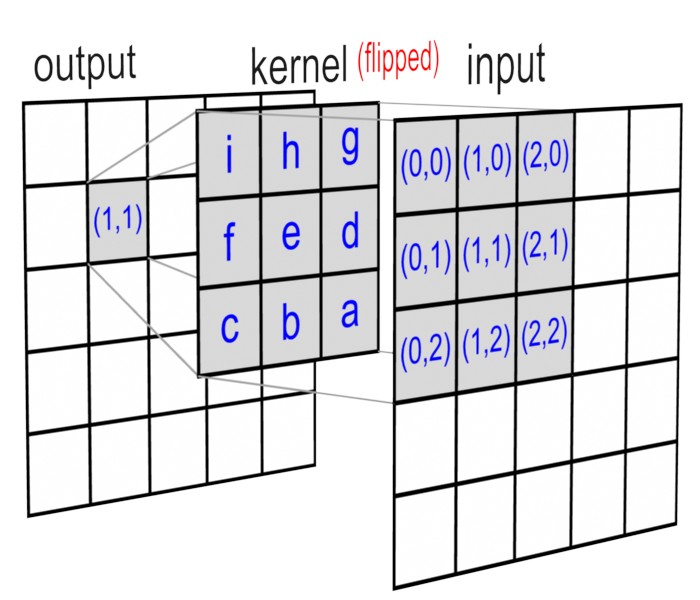
矩阵卷积, 一般在图像处理中用的比较多. 例如图像的锐化、边缘检测、高斯模糊等用的都是3x3的矩阵,里面各位置的数值不一样而已. 参见: https://en.wikipedia.org/wiki/Kernel_(image_processing)
进一步, 可以参看图像卷积与滤波的一些知识点 一文.
3.梯度的定义
“你站在半山上腰, 四周转一圈, 向上最陡的方向就是梯度……” – 章纪民
梯度不是个度, 是个”方向”(向量).
4.最小梯度法
(略)
问题的表述
举例, 以16x16黑白图像, 10张图训练集(4张图为猫, 6张图为狗), 区分猫狗
在这里,以一个二维向量定义
[1, 0] := 猫,
[0, 1] := 狗
拟合一个函数 f 使得
f(猫的图像) -> [1, 0],
f(狗的图像) -> [0, 1]
其中,描述函数f所需要的参数有很多, 我们用一个很大的矩阵A把它存下来.
机器学习的 结果, 即是函数 f (事实上, 是描述函数f的所有参数A)
小结
训练: 输入训练集, 求出f的参数(矩阵A)
训练结果: f的参数(即矩阵A)
训练集
输入的一张16x16像素点,黑白(色阶由0-255来表示)图像可表述为: 一个16行,16列的矩阵, 矩阵中的元素是其像素的灰度值.
[
(猫1的图像, [1,0]), (猫2的图像, [1,0]), (猫3的图像, [1,0]), (猫4的图像, [1,0]),
(狗1的图像, [0,1]), (狗2的图像, [0,1]), (狗3的图像, [0,1]), (狗4的图像, [0,1]),
(狗5的图像, [0,1]), (狗6的图像, [0,1])
]
训练过程
1. 对图像进行处理
选定一个3x3的矩阵(即卷积核), 使用数字图像处理中的卷积, 对原图像进行作用. (理解成Photoshop中的锐化、模糊、边界保留等等滤镜)
在这里, 只作一次卷积(滤镜), 就是一层神经网络.
2. 定义 Loss Function
下面我们定义出一种Loss Function:
L = loss_function( f(输入), 期望的结果 )
3. 求解
那么, 我们的问题就是, 已知loss_function, 和一些训练集. 通过改变函数 f 的参数(存于矩阵A), 来使得loss_function的输出L最小.
也就是求loss_function的极值 : (使用梯度下降法)
随便取一个点, 看往那边走下降最快…然后走一小步… – vuryleo
实际上就是一个搜索问题.
(更进一步) 多层神经网络
再找一个图像卷积的矩阵, 把上一步的结果拿过来, 再过一个新的卷积矩阵(滤镜), 再对新的loss_function求解.
使用
拿着你构建出来的这个 f (那个大矩阵A, 其中也包括了卷积核):
作用到一张新图上, 结果接近[0,1], 则是狗, 结果接近[1,0], 则是猫.
拿着训练好的模型使用的过程, 不需要很大的计算量.
黑话集
“诶, 这个丹炼出来了啊”
“什么是丹, 什么是炼, 什么又是出来?”
bigeagle: “丹, 就是那一堆参数不确定的矩阵, 炼, 就是这个训练的过程, 炼出来, 就是能完成这个分类”
“是不是有点过拟合?”
什么特么又叫过拟合? 拟合什么? 由哪里拟合到哪里? 过是怎么讲?
“炼丹啊,玄学”
呸.
进一步
有了以上的准备知识, 可以看下面几个DEMO:
- http://cs.stanford.edu/people/karpathy/convnetjs/demo/mnist.html 1
- http://scs.ryerson.ca/~aharley/vis 1
- http://playground.tensorflow.org/ 2
- http://colah.github.io/posts/2014-03-NN-Manifolds-Topology/ 3
Google TensorFlow. 以及TensorFlow的图形化调试工具TensorBoard.
Tensor: 张量. 2阶张量为矩阵, 1阶张量为向量, 0阶张量为标量.
逸闻:
今天在Google Developer Day上听TensorFlow的讲座, QA环节, 台下有人提问.
第一个人以为训练模型和使用模型的计算量同等大小… 以为现在手机上能够用上模型来判别,是因为计算量已经足够大了. 所以就问手机上能跑TensorFlow训练模型吗
第二个问题: 一个人站起来说, 你们搞的这个Tensor…..Tensor什么来着…. 很好啊!
这也是今天晚上我想搞明白机器学习原理的动力之一吧….. 总得有人要去做大家都懒得做的科普工作
后记
曾经有好几次, 我向”炼丹”圈内比较厉害的同学诚意地请教了几次机器学习的原理. 他们总是一副”啊这你都不懂啊” “啊这你不用懂” “啊这你就不懂了” “啊这个是玄学” 这样的态度.
我非常生气.
太阳底下无新鲜事. 我想, 我还是有这一点基本的智商的. 于是, 在这样一个周四的晚上, 我决定尝试用最少的数学知识, 从一些真正愿意分享知识的人那里, 搞明白它的基本原理. 但求之后再见到这些炼丹流氓们, 能够不再被他们讹诈. 这也是本文整理出来的初衷. 感谢bigeagle花一个晚上的时间帮我讲明白.
TUNA最宝贵的风气,是我们对获取知识平等权利的尊重. 记得2011年听肖骐做讲座的时候, 他总是会觉得你听不懂是他的事, 而不会说出”这你都不懂?”这样的话. 现在的TUNA里也是这样的风格. 术业有专攻, 闻道有先后. 学代数的时候, 学不会, 看到一篇文章, 讲日本的代数学家4, 也是看书看不懂, 就一遍一遍的抄课本, 后来也获得了很大的成就. 张贤科老师说, 爱因斯坦当年也是反应都比大家慢一点, 多想一点, 后来人家就是做出了一些结果.